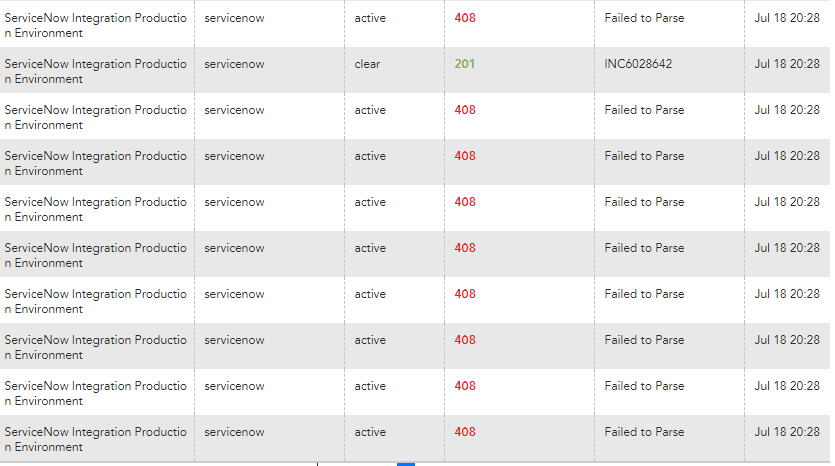
If you’re talking about the alert rate limit on the escalation chain, it does queue them up. That’s been my experience at least. We’ve had a few cases where I’ve pushed bad code causing several thousand alerts. They all go to email, but I suppose the rate limit should behave the same. Let’s say your limit is 200 alerts / 10 minutes and you have 1000 alerts.
First you get 200 notifications. You immediately get a “escalation chain throttled” notification. This isn’t an alert, but is treated like one by the escalation chain, has an alert id and everything. I would assume you’d get the same thing in an API push to any ticketing system, but I have no idea what the payload would look like, not having seen that happen with my ticketing system yet.
Then when 10 minutes goes by, you get the next 200 notifications plus a “throttled” notification.
Then when 10 minutes goes by, you get the next 200 notifications plus a “throttled” notification.
Keep in mind that you could have other alerts opening during this time. Eventually you get to a point where the last queued alerts are sent, but you may get into a cycle where the last 10 minutes had 198 alerts and 2 minutes later you get another 10 alerts. In that case, 2 more alerts would be sent immediately (plus a throttle notification) and after a while you’d get the other 8.
That’s been my experience. YMMV. I’ve seen it in email notifications, but that’s where my alert storms happen.