Alerts for down and degraded sites
Currently we have LM setup to email Cherwell (ticketing system) to open a ticket based on ping. Our ping rule is 20 / 70 / 90.
Downside is if the site is going up and down and the pings just drop for a short amount of time, the alert clears and comes back resulting in multiple tickets for the same issue or a ticket for an "outage" that cleared right away. Our Cherwell setup is not smart enough to not make multiple tickets with the same subject, so the issue cannot be fixed on the Cherwell side.
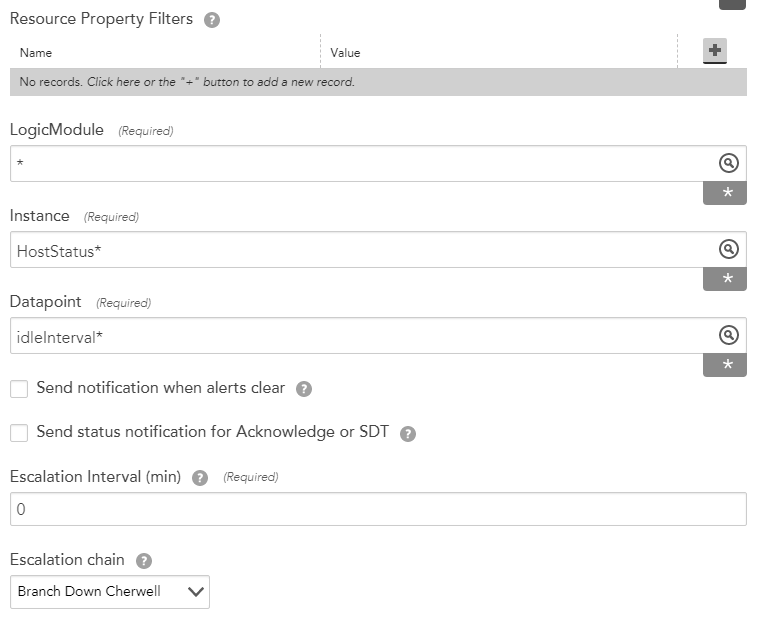
I was thinking to set the down branch tickets to open based on Host Status instead. I see this alert when branches actually go down and seemed like a good metric to use.
I would also like a degraded ticket if the ping is bad over a longer period of time. Currently I'm not really sure what the ping period is for calculating the ping percent. Is it out of every 5 pings or 100 pings or 5mins worth? It would be good to have a ticket for if the ping is over 100ms for 5min and/or if the pings drop 10% of a 5min period. (I'm guessing on the specifics for these, so open to suggestion on better degrade metrics.)
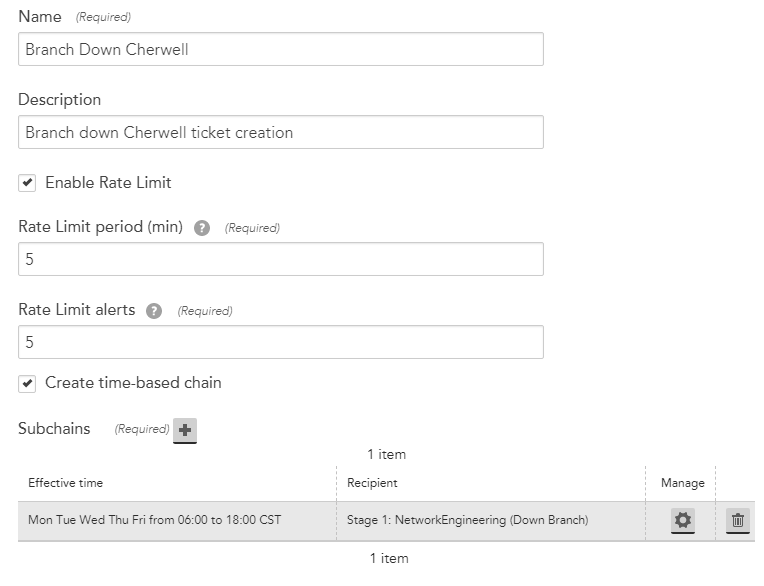
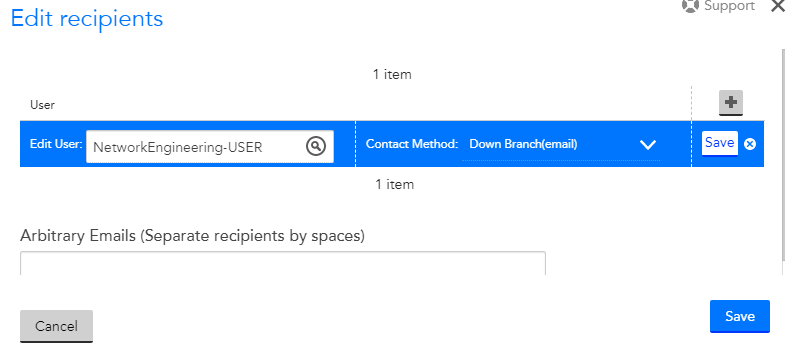
I didn't originally setup the Alert Rules and Escalation Chains in LM so there seem to be a lot of redundant and oddly setup rules and chains since we are still pretty new to LM and still learning. Trying to clean it up and improve the alerts without breaking the current alerting.
I started with trying to make a Alert Rule for down branches with Host Status. Originally the down branch rule based on ping was the top rule (5) so I copied the setup of that rule and made this rule at 4. The only difference is Instance = HostStatus* (was Ping*) and Datapoint = idleInterval* (was PingLossPercent*). However, the emails in the ticket still have the ping info in them, so I'm not sure if they are actually hitting and using the rule as intended.