Forum Discussion
5 years ago
15 hours ago, Mike Moniz said:I guess I'm not clear, are your existing gap issue from monitoring remote sites from a more central location, or that the collectors are overloaded because there are not enough? Or Both? Also can you just run the collector servers directly in Azure? That would also lower your bandwidth use over the MPLS.
You might be able to push each collector to have more instances then you list. I can't check anymore but I think I've pushed 30k+ instances per large Windows collectors (before redundancy) in some situations. I personally tend to go with larger collectors rather than have tons of small size ones, but you still need to make sure you have the redundancy for collector failures into account.
But the good thing is that you can add and remove collectors on-the-fly without downtime. You can start with fewer then add more if you see the load it too much, or add too many and remove some if they are too idle. Although that might not help when working out budgets.
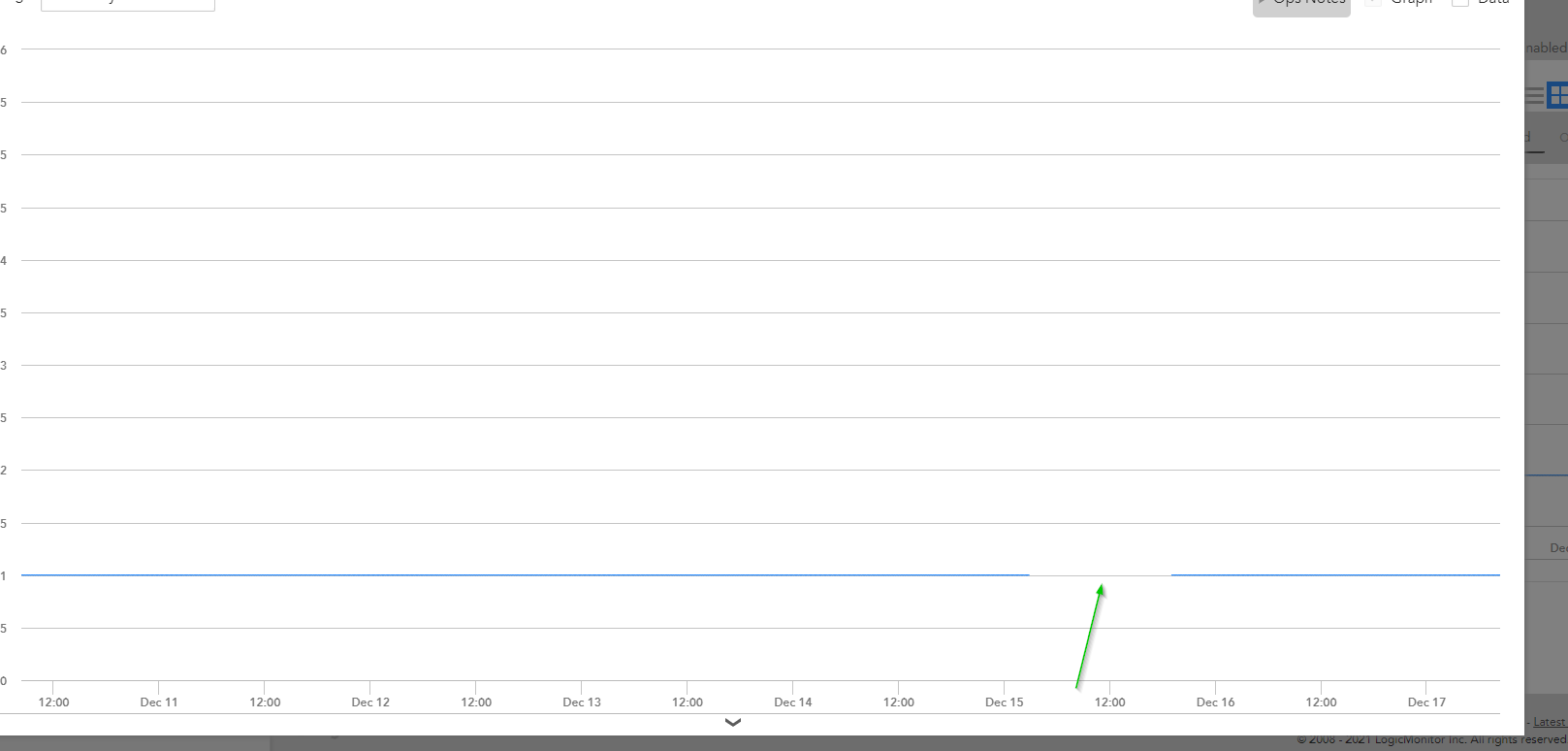
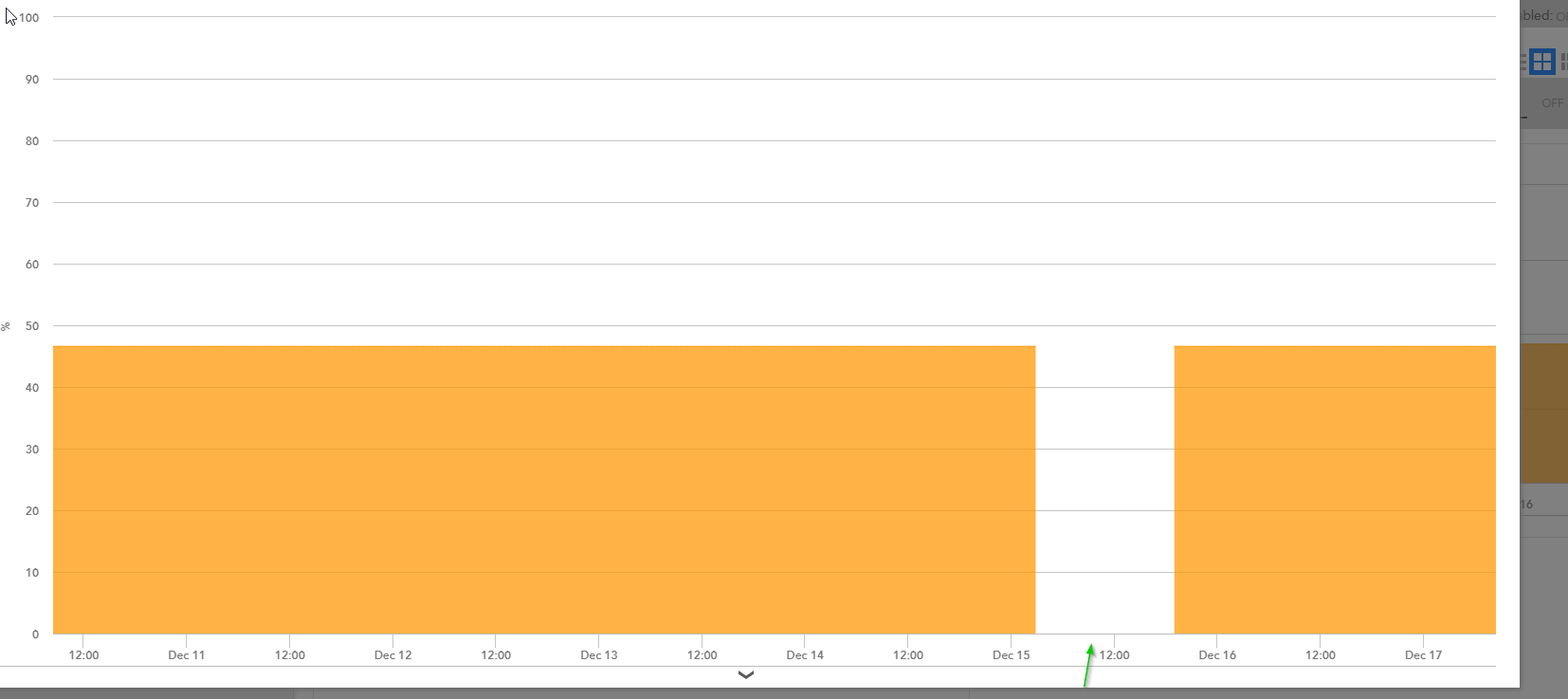
In our environment we don't have bandwidth or latency issues, and all our collectors are 2xl, and they average around 8k instances each, so the collectors aren't overloaded. the pics below are from a device who has 5ms latency to the collector and it's showing gaps from 2 different datasources at the same time. my questions are the following:
1. Are gaps in polling expected behavior in LM, is this something we should just get used to, does your environment constantly have them?
2. If they can be fixed, what deployment model above is recommended for moving into azure so we don't see them any longer?