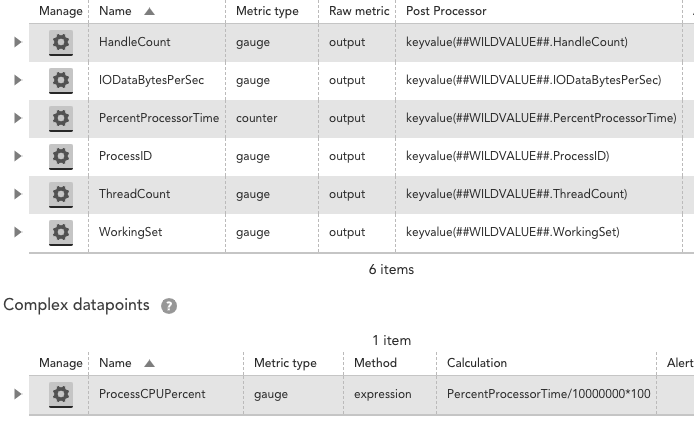
Expert
ExpertDatasource to monitor Windows Services/Processes automatically?
Hello,
We recently cloned 2 Logic Monitor out of the box datasources (name -> WinService- & WinProcessStats-) in order to enable the 'Active Discovery' feature on those.
We did this because we've the need to discover services/processes automatically, since we don't have an 'exact list' of which services/processes we should monitor (due to the amount of clients [+100] & the different services/solutions across them)
After enabling this it works fine & does what we expect (discovers all the services/processes running in each box), we further added some filters in the active discovery for the services in order to exclude common 'noisy' services & grab only the ones set to automatically start with the system.
Our problem arrives when these 2 specific datasource start to impact the collector performance (due to the huge amount of wmi.queries), it starts to reflect on a huge consumption of CPU (putting that on almost 100% usage all the time) & that further leads to the decrease of the collector performance & data collection (resulting in request timeouts & full WMI queues).
We also thought on creating 2 datasources (services/processes) for each client (with filters to grab critical/wanted processes/services for the client in question) but that's a nightmare (specially when you've clients installing applications without any notice & expecting us to automatically grab & monitor those).
Example of 1 of our scenarios (1 of our clients):
- Collector is a Windows VM (VMWare) & has 8GB of RAM with 4 allocated virtual processors (host processor is a Intel Xeon E5-2698 v3 @ 2.30Ghz)
- Currently, it monitors 78 Windows servers (not including the collector) & those 2 datasource are creating 12 700 instances (4513 - services | 8187 - processes) - examples below
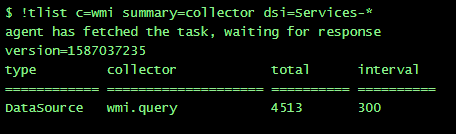 This results in approx. 15 requests per second
This results in approx. 15 requests per second
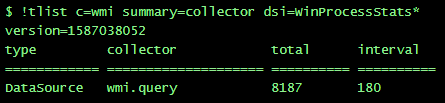 This results in approx. 45 requests per second
This results in approx. 45 requests per second
According to the collector capacity document (ref. Medium Collector) we are below the limits (for WMI), however, those 2 datasource are contributing A LOT to make the queues full.
We're finding errors in a regular basis - example below

To sum this up, we were seeking for another 'way' of doing the same thing without consuming so much resources on the collector end (due to the amount of simultaneous WMI queries). Not sure if that's possible though.
Did anyone had this need in the past & was able to come up with a different solution (not so resource exhaustive)?
We're struggling here mainly because we come from a non-agent less solution (which didn't faced this problem due to the individual agent distributed load - per device).
Appreciate the help in advance!
Thanks,