 Expert
ExpertCisco EIGRP Peer alarm(s) not being supressed?
Hello,
We've noticed the Cisco EIGRP PeerDown alarm(s) aren't being suppressed if the actual device goes down on LM.
When lost SNMP connectivity to one of our routers, it started returning PeerDown alarms (since SNMP wasn't responding, causing the 'NoData' condition at the 'upTime' datapoint).
This becomes an issue because the actual datapoint that checks the Peer status, bases itself on the data retrieved by the 'upTime' datapoint (which at this point, is as 'NoData).
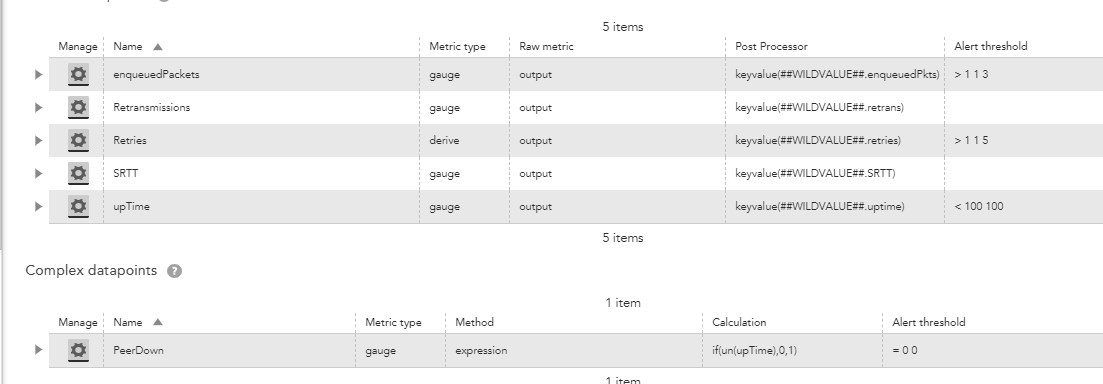
Basically, if the 'upTime' doesn't return data (which happens if the actual device goes down) it'll trigger an alarm for the PeerDown instances (since it'll always return False).
LogicMonitor only sees the actual device as 'down' after 5 minutes (when not retrieving data). This DS will alarm first (since the PeerDown will return an alarm on 2 consecutive tools - which means 3 minutes).
As per the documentation, all the alarm(s) emanating from the host will be suppressed. My question here (just to make sure) is, this will only be the case for alarms that hit 'AFTER' the host down condition correct?
If that's true, how can we surpass this without having to increase the time that 'PeerDown' alarms took to appear in the console?
Is there any type of expression that we can use in that ComplexDatapoint (instead of the current one).
Because, currently the fact of this device being down, caused 100 alarm(s) on the console (since it's a central point for our EIGRP routing).
Thank you!
Regards,


