Forum Discussion
99 Replies
 Steve_FrancisFormer Employee
Steve_FrancisFormer EmployeePublished, locator 24KKNG
Updated the documentation article above. Please let me know if there are any other issues.
- 47 minutes ago, Steve Francis said:
Published, locator 24KKNG
Updated the documentation article above. Please let me know if there are any other issues.
Working beautifully now!
Has using an empty value for the depends_on property been tested to have negative results? My testing shows no ill effect. Adding this property at the group level obviously speeds deployment. However if the primary device is within the group I don't want to make it dependent on itself. Adding the depends_on property to the primary device with an empty value seems to resolve this.
 Keimond
KeimondNeophyte
Definitely a step in the right direction for LM.. now we just need to be able to use this for stuff that goes down but doesn't have an SDT lol... I assume the same logic can be applied but that involves deeper changes than data sources :)/emoticons/smile@2x.png 2x" title=":)" width="20">
I may have missed it but if it hasn't been requested, besides host dependencies, we should have service dependencies. There should also be multiple dependencies.
* Host 03 depends on Host01
* Host 04 depends on Host01 AND/OR Host02
-- (and) don't alert Host04(and services) if Host01 and/or Host02 are down.
-- ( or) don't alert on Host04 if just Host01 or Host02 are down.
* Service07 depends on Service05
* Service10 depends on Service05
* Service08 depends on Service01 AND/OR Service02
-- (and) don't alert on service 08 if Serviec01 and/or Service02 are down.
-- ( or) don't alert on service08 if just Service01 or Service02 are down.and the list could go on with multiple scenarios...
* Service09 depends on Host 01
* Service12 depends on Host 01 AND/OR Host02
* Host03 depends on Serivce04
* Host03 depends on Service02 AND/OR Service06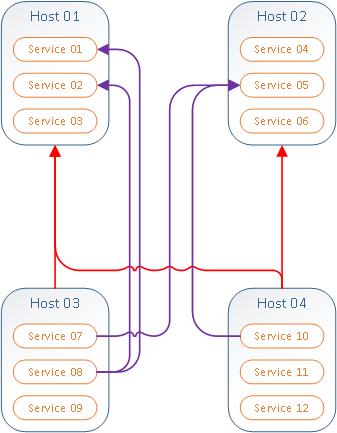
 mnagel
mnagelProfessor
@Steve FrancisI finally got around to deploying and testing this, but it is not going well. I tried a poll now on the Assign DS and I get "Fail to get the script result - sseId:0 NullPointerException: Cannot invoke method getBytes() on null object". Is this being impacted by the v2 API changes?
- mnagel13 minutes ago, mnagel said:
@Steve FrancisI finally got around to deploying and testing this, but it is not going well. I tried a poll now on the Assign DS and I get "Fail to get the script result - sseId:0 NullPointerException: Cannot invoke method getBytes() on null object". Is this being impacted by the v2 API changes?
Never mind -- I waded through the docs more thoroughly and found the section about defining the API credentials.
- Chris_SternbergFormer Employee
Hi Everyone! Chris Sternberg here and I'm the PM working on the Alert Dependency & Suppression project.
We are working on an algorithm for alert dependency based on resource "reachability" using the relationships established by topology and would appreciate any input you have to offer. There are two primary issues we are trying to address: 1. facilitate root cause analysis by identifying the resource alerts that initiated an alert incident 2. prevent alert noise by suppressing routing for non-actionable/dependent alerts (we are starting out with SDT but are researching an alert dependency tagging approach and configuration to use instead of SDT)
The first step in the process is the addition of an entry-point property that selects a resource as a parent for all connected resources. Using the topology relationships any connected resource can then be identified as a dependent as well as the number of steps it is removed from the entry-point. When the algorithm runs, if a critical PingLossPercent alert exists (i.e. is the resource reachable) on any dependent resource it checks its connected resources that are one step closer to the entry point (i.e. its upstream neighbor/parent as opposed to the "umbrella" parent entry-point), and if any of those are also in a critical PingLossPercent state, we determine its state is dependent and the resource is placed into SDT. The process continues up the chain until there are no other parent devices that are in a critical "reachability" alert state, or the entry-point resource is reached. That last resource in a critical state is identified as the root/originating cause and any neighbor/parent along the chain that was one step closer to the entry point is identified as a direct cause. For any alerts placed into SDT by the auto-SDT applied to the resource, the originating cause and direct cause are recorded in an SDT note.
High level logic flow:
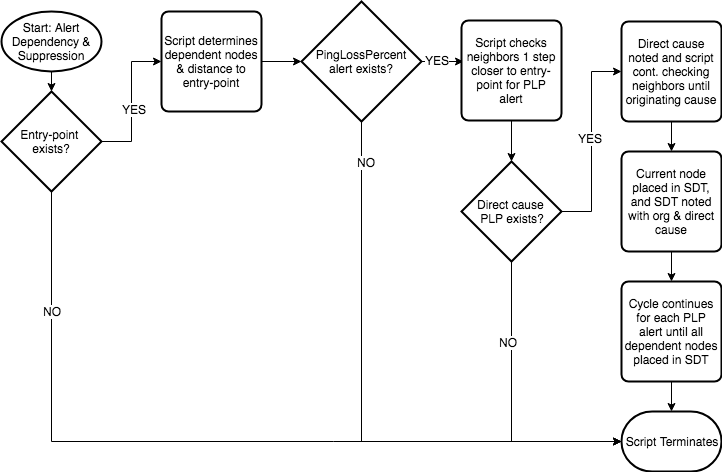
This approach is reactive in that an alert has to exist for a child as well as for a parent in order for the child to be suppressed/placed into auto-SDT. The datasource approach discussed in the posts above is more proactive in that all dependents are placed into SDT based on a parent being in a critical alert state. Neither approach is 100% effective in preventing alerts on dependents in part since there is no guarantee that a parent will be in an alert state before a child is in an alert state. The algorithm is more reactive and only SDT's resources actually in alert, and in turn facilitates root cause analysis by identifying an originating cause to the alert incident. The datasource is more proactive and suppresses child alerts via SDT preventing additional notifications.
As mentioned we are researching a method whereby we tag alerts for both parent and child resources with metadata to identify cause and dependents. We would allow for routing configuration for alert notifications based on the alert dependency tag metadata.
A main issue for the suppression of alert notifications for dependent or non-actionable alerts is timing since instances are not all polled in the same interval nor are they polled based on dependency. In order to try and prevent routing for as many dependent non-actionable alerts as possible we are considering an option to delay routing for resources that are part of a parent/child dependency chain. The notifications could be delayed until we have identified cause and dependent alerts to be routed based on user configuration. Critical alerts for which routing is suppressed based on dependency, could be routed later should the critical alert remain active once a parent resource is no longer down.
Questions for feedback:
1. What do you think of an approach that would delay routing for a short amount of time (TBD) in order to allot enough time for an alert dependency incident to get into full swing and allow the dependency algorithm to tag alerts with relevant cause and dependent metadata? This metadata would be used to determine what notifications should be routed and which should be suppressed.
2. When a critical “reachability” alert occurs for resource(s) in a dependency chain, should other alerts that occurred X #number seconds/minutes prior to the first “reachability” alert also be considered part of the alert dependency incident?
3. In your experience, how quickly does an alert dependency incident fully manifest itself in LM? Meaning from the first parent device going down, to the last dependent going down as well, how long does this typically take? Of course this can depend on what types of resources are involved so any input in that area and whether timing falls in range of (A) Less than 1 min (B) 1-3 mins (C) 3-5 mins (D) more than 5 mins, would be helpful.
4. We are starting with Ping | PingLossPercent datapoint. What other datapoints are you using as indicators of resource or instance “reachability”?
I greatly appreciate any feedback and additional questions!
Thank you,
Chris  Mosh
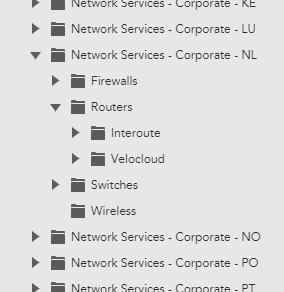
MoshWe organise each countries network CIs (configuration items) into groups by firewalls, routers, switches and wireless (see attached image). What we need to be able to do is somehow say that if any CI under the Routers group and subgroups is down (ping loss and host status), then alerts should be suppressed for the Firewalls, Switches and Wireless groups and sub-groups.
Will what you are proposing enable us to do this?
- Chris_SternbergFormer Employee
Hi @Mosh
Alert suppression based on dependencies relies on topology, so provided that we are able to discover the connections between the routers and devices that are dependent on them for connectivity, then we would be able to enable it for the network devices in those groups. You won't manually define which device groups are parents and which are children, but identify the core entry-point devices, in your case this would appear to be the routers, and any discovered device connections to those routers would be categorized into a dependent parent/child hierarchy. Meaning that if you have a core router connected to a firewall which is connected to a switch which is connected to a server, where each connection is an additional step removed from the core router, each device would serve as a parent for the next device in this hierarchy. So this means that if a router goes down then all alerts for the child firewall/switch/server devices would be identified as dependents, but also if just the switch went down then the alerts for the server would be identified as dependent to the switch going down.
The current phase for topology is focused on CDP and LLDP discovery protocols so those would need to be supported by the devices in question. At this time the alert dependency functionality with use of SDT that I described in my previous post is only available for NG portals, but since you have a sandbox let me know if you'd like to get your hands on it for testing as I would love to get your feedback.
Also, I want to clarify some points around the term alert "suppression". While we have started with the use of SDT as the best tool we currently have to suppress alert notifications, we are not looking to prevent or disable alerts for dependent resources. Instead we want to identify or tag dependent alerts so that you can configure how you view them within LM and route them externally for notification. The goal is to provide an "area of effect" for an alert storm and categorize the alerts based on their role as root or dependent causes. It would then be up to the user whether dependent alerts should be shown in various widgets, and if notifications for dependent alerts should be routed for notification. Ultimately, alerts for root/originating causes and their dependents would be displayed as such in the Alerts page.
I would love to get your feedback on the functionality we have so far and where we're headed so please let me know if you have additional input and whether you'd be interested in testing the functionality as it stands now in your sandbox portal.
Thank you,
Chris - Mosh
Thanks @Chris Sternberg
Will the topology module be a licensed module or included as part of a forthcoming update?