Take this 2-minute survey to shape the future of observability
Where Are You on Your Observability Maturity Journey? Help us better understand what observability use cases matter most to you and your company right now—and your priorities for 2025. Our Observability Benchmark Survey explores: ✅ Key observability use cases and priorities ✅ How organizations are evolving their strategies ✅ The impact of automation and AI in observability Your insights will shape future LogicMonitor solutions, product innovation, and industry programming. Take the survey now!553Views2likes1Comment
Assistance Request to Resolve "No Data" Error on Devices Monitored via Batchscript in Collectors
Dear Engineers, I am reaching out for your assistance to resolve an issue affecting multiple devices in our LogicMonitor portal (logicmonitor.com), where several datapoints are displaying a "No Data" message. Upon review, we noticed that tasks executed under “batchscript” are returning the value "False," indicating that despite various adjustments and recommendations, the Collectors are not successfully executing all tasks related to “batchscript,” which affects the retrieval of information for reports, graphical event analysis, alerts, etc. We have examined the associated graphs, specifically the LogicMonitor_Collector_DataCollectingTasks-batchscript graphs for the five (5) assigned Collectors, and observed high rates of unexecuted tasks. Below are the actions taken so far: Actions Taken: - Adjusted properties for prioritization on the collectors: Property Suggested Value Benefit collector.threads.poolsize 100 Improves concurrency for general tasks. collector.threadpool.size 50 A larger pool allows the collector to handle more tasks simultaneously. collector.cache.max_objects 15000-20000 Increases temporary cache storage capacity. collector.enable_batching true Optimizes data transmission in batches. collector.device.batch.size 30 Processes more devices at once, improving performance. collector.batchscript.retry 3 Enhances fault tolerance for script execution. collector.batchscript.timeout 30 A longer timeout ensures complex scripts can execute without interruptions. collector.batchscript.pollinginterval 300 Balances data collection frequency and resource usage. collector.batchscript.maxconcurrenttasks 10 Allows parallel execution of scripts across multiple devices. collector.snmp.retries 3-4 attempts Improves reliability in networks with packet loss. collector.snmp.timeout 5 seconds Increases stability for SNMP queries in slower networks. collector.snmp.parallelrequests 10 Improves monitoring speed by processing more requests in parallel. collector.snmp.fetchthreads 30 Enhances concurrency for SNMP data collection. interface.snmp.method getconcurrent Speeds up SNMP data collection. paloalto.threadpoolsize 10 Adjusts thread count when monitoring Palo Alto firewall aspects. cisco.ipsec.aggtun.timeout 10 Tweaks monitoring behavior for IPSec tunnels. cisco.ipsec.aggtun.threadpoolsize 10 A larger pool allows the collector to handle more tasks in parallel. A larger pool allows the collector to handle more tasks in parallel. - Constant review and updates of**: DataSource, EventSource, ConfigSource, PropertySource, AppliesTo, and SNMP SysOID Maps for each device brand. - Adjustment of batchscript task processing for all collectors**, updating `collector.batchscript.threadpool` and `collector.batchscript.timeout` values: - (1) **Collector-Large**: 127 Devices - `collector.batchscript.threadpool=200`, `collector.batchscript.timeout=360` - (1) **Collector-Medium**: 15 Devices - `collector.batchscript.threadpool=180`, `collector.batchscript.timeout=360` - (1) **Collector-Small**: 8 Devices - `collector.batchscript.threadpool=170`, `collector.batchscript.timeout=360` - (1) **Collector-Small**: 14 Devices - `collector.batchscript.threadpool=170`, `collector.batchscript.timeout=360` - (1) **Collector-Small**: 20 Devices - `collector.batchscript.threadpool=170`, `collector.batchscript.timeout=360` Although these changes have partially improved the situation, the error persists in executing batchscript tasks for several devices. This suggests that the issue might be related to the **collector size** and the **hardware resources** allocated. Since **batchscript** is the primary method used to gather data for most of our devices, we would appreciate your guidance on the following: Key Questions: What is the optimal resource allocation for each of the collectors** to prevent task execution errors? We are currently monitoring over 200 devices, with an annual growth rate of 15%. Is there a formula or method to determine how many batchscript tasks are successfully executed versus failed attempts?** This would help us assign appropriate collector sizes and hardware resources to ensure tasks are completed successfully, considering the 15% growth rate. We are monitoring devices under the following setup: - **CollectorOn-Premises1Site**: 300+ devices - **CollectorOn-Premises2Site**: 75+ devices - **Collector-AWS**: 50+ devices - **Collector-GCP**: 50+ devices - **Collector-Azure**: 50+ devices How can we determine the appropriate collector size based on the number of devices to be monitored?** This will help us allocate hardware resources to integrate more devices into each collector.I look forward to your comments and technical recommendations for optimizing the collectors.76Views2likes0Comments
WhatsApp Group SMS Alerts
Hi There, Has anyone been able to set SMS alerts to go to a WhatsApp group? LM support suggests it can be done via a custom HTTP delivery but I need to reach out to WhatsApp support to help set it up. https://www.logicmonitor.com/support/alerts/integrations/custom-http-delivery76Views0likes2CommentsCan we have "Most Recent" be the default view?
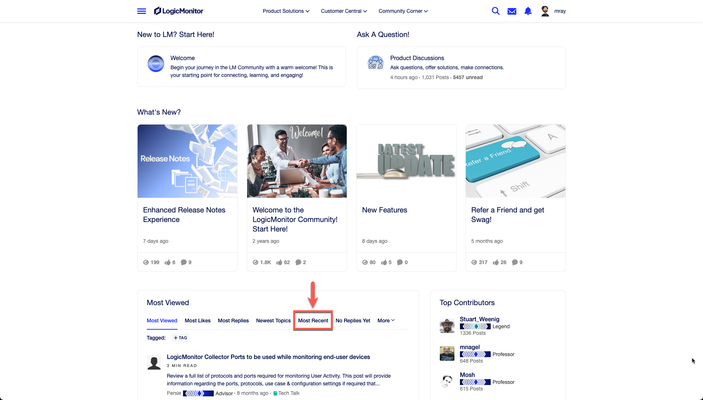
Similar to The feed on the community feedback page is only "top content" | LogicMonitor - 15063 But looking at the main home page, which is currently defaulting to "Most Viewed": Curious though if it's just me that thinks "Most Recent" makes the most sense as the default?52Views3likes3Comments
Add Reply Preview to Account "Your replies" Page | Suggestion
Howdy! I would like to suggest adding a preview of the reply you made when viewing the “Your replies” section of your account. In its current form, it only includes the message you replied to, not your own reply. This makes it a bit trickier to browse your replies, if you don’t remember what you had said.73Views10likes5Comments
Plain text option in code widget or monospace font style option
Sometimes we need to paste in code output or text that shouldn’t be formatted the way normal text is formatted. We need either an “unformatted” language to choose from in the code widget, or we need a text option that is monospace (where every character takes up the same width so that indentation is rendered properly). For example, this log output looks like this in a code widget: Using the code widget and choosing “not set”, which I expected to have no color coding. This is not what it should look like. Interestingly, if I paste the same block of text here, it’s not color coded like it is in that post. This leads me to believe that all code blocks within the same post use the same language, even if the code widget is set to “not set”. >>> response = create_group("SDK Test",812,{"prop1":"1","prop2":"2"}) [2023-02-21 16:30:11] API SDK POST: Created resource group Customers/Longhorn Smokers/SDK Test (854) >>> response = create_group("SDK Test",812,{"prop1":"1","prop2":"2"}) [2023-02-21 16:33:06] SUMMARY: Customers/Longhorn Smokers/SDK Test already exists in LM with all the correct properties, moving on... >>> response = create_group("SDK Test",812,{"prop1":"1","prop2":"2"}) [2023-02-21 16:33:43] API SDK PATCH: Patched device group SDK Test >>> debug = True >>> info = True >>> response = create_group("SDK Test",812,{"prop1":"1","prop2":"2"}) [2023-02-21 16:35:57] DEBUG: Group SDK Test exists in LM (854), checking if attributes match... [2023-02-21 16:35:57] DEBUG: Property prop1 matches attribute already in LM [2023-02-21 16:35:57] DEBUG: ================================================================================ [2023-02-21 16:35:57] DEBUG: prop1: 1 [2023-02-21 16:35:57] DEBUG: prop1: 1 [2023-02-21 16:35:57] DEBUG: ================================================================================ [2023-02-21 16:35:57] DEBUG: Property prop2 matches attribute already in LM [2023-02-21 16:35:57] DEBUG: ================================================================================ [2023-02-21 16:35:57] DEBUG: prop2: 2 [2023-02-21 16:35:57] DEBUG: prop2: 2 [2023-02-21 16:35:57] DEBUG: ================================================================================ [2023-02-21 16:35:57] DEBUG: There is no AppliesTo that we want to patch in. [2023-02-21 16:35:57] SUMMARY: Customers/Longhorn Smokers/SDK Test already exists in LM with all the correct properties, moving on... [2023-02-21 16:35:57] DEBUG: 854: Customers/Longhorn Smokers/SDK Test: [{'name': 'prop2', 'value': '2'}, {'name': 'prop1', 'value': '1'}] >>>117Views5likes8Comments