Various Linux distros - SNMP disk OID change
Hi LM Community
I'm having a issue that I've searched these forums and the web, but unable to find anyone who have a solution on this matter.
We are monitoring Linux server with SNMP, to be specific the DataSources we are having problems with is:
https://www.logicmonitor.com/support/monitoring/os-virtualization/filesystem-monitoring
- SNMP_Filesystems_Usage
- SNMP_Filesystems_Status
These 2 DataSources are the "new ones" when it comes to Linux monitoring and disk status + usage, we have removed all of the old DataSources described in the article.
The issue is when the SNMP service is restarted, or the Linux machine is restarted, then SNMPD allocated what seem to be random OIDS to the disks each time.
I've created a support case with LogicMonitor, but it got shrugged off as they haven't heard of this issue before, I cannot believe that we are the only ones that has seen this problem.
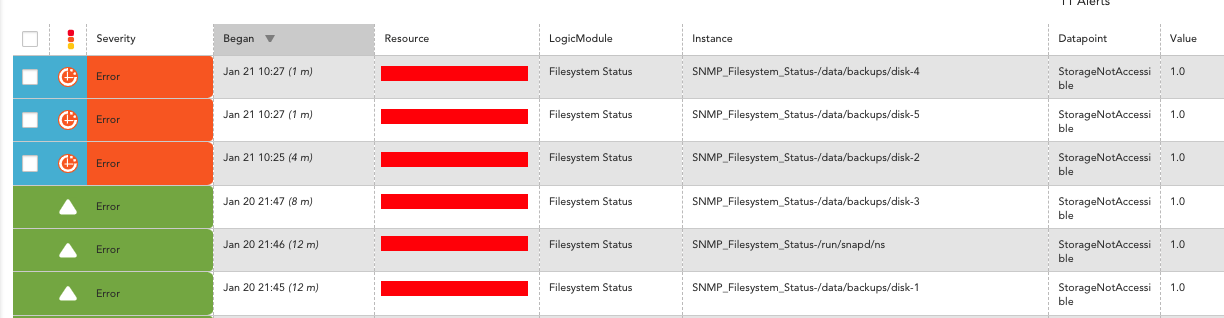
Example alarm is:
Host: <REDACTED> Datasource: Filesystem Capacity-/run/snapd/ns InstanceGroup: @default Datapoint: StorageNotAccessible Level: warn Start: 2021-12-10 15:50:22 CET Duration: 0h 12m Value: 1.0 ClearValue: 0.0 Reason: StorageNotAccessible is not = 1: the current value is 0.0
We have seen this on CentOS, Ubuntu 16, 18, 20. Sometimes it's multiple disks, other times it doesn't happen. The solution is to run active discovery on the resource again.
I think part of the problem is that the WildCard used is the SNMP OID that changes, if the WildCard was the mount point name, this would not had been an issue.
I've partly solved this by changing the discovery schedule on the DataSource's from 1 day, to 15 minutes, then the monitoring works again.
Do anyone have any idea what could be causing this?
Regards.