Forum Discussion
Chris_Sternberg
7 years agoFormer Employee
Hi Everyone! Chris Sternberg here and I'm the PM working on the Alert Dependency & Suppression project.
We are working on an algorithm for alert dependency based on resource "reachability" using the relationships established by topology and would appreciate any input you have to offer. There are two primary issues we are trying to address: 1. facilitate root cause analysis by identifying the resource alerts that initiated an alert incident 2. prevent alert noise by suppressing routing for non-actionable/dependent alerts (we are starting out with SDT but are researching an alert dependency tagging approach and configuration to use instead of SDT)
The first step in the process is the addition of an entry-point property that selects a resource as a parent for all connected resources. Using the topology relationships any connected resource can then be identified as a dependent as well as the number of steps it is removed from the entry-point. When the algorithm runs, if a critical PingLossPercent alert exists (i.e. is the resource reachable) on any dependent resource it checks its connected resources that are one step closer to the entry point (i.e. its upstream neighbor/parent as opposed to the "umbrella" parent entry-point), and if any of those are also in a critical PingLossPercent state, we determine its state is dependent and the resource is placed into SDT. The process continues up the chain until there are no other parent devices that are in a critical "reachability" alert state, or the entry-point resource is reached. That last resource in a critical state is identified as the root/originating cause and any neighbor/parent along the chain that was one step closer to the entry point is identified as a direct cause. For any alerts placed into SDT by the auto-SDT applied to the resource, the originating cause and direct cause are recorded in an SDT note.
High level logic flow:
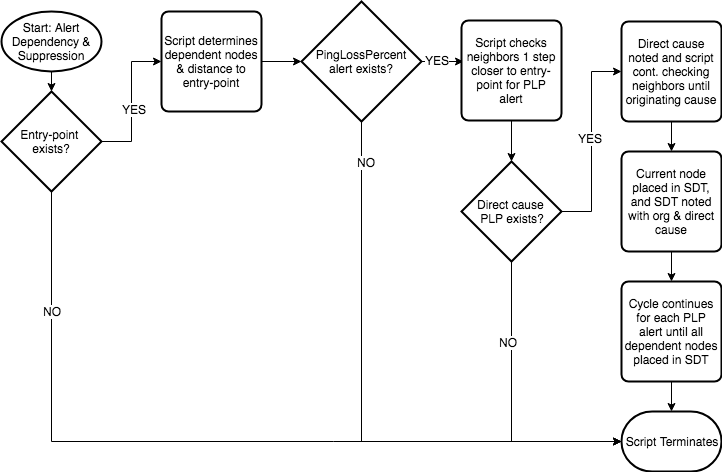
This approach is reactive in that an alert has to exist for a child as well as for a parent in order for the child to be suppressed/placed into auto-SDT. The datasource approach discussed in the posts above is more proactive in that all dependents are placed into SDT based on a parent being in a critical alert state. Neither approach is 100% effective in preventing alerts on dependents in part since there is no guarantee that a parent will be in an alert state before a child is in an alert state. The algorithm is more reactive and only SDT's resources actually in alert, and in turn facilitates root cause analysis by identifying an originating cause to the alert incident. The datasource is more proactive and suppresses child alerts via SDT preventing additional notifications.
As mentioned we are researching a method whereby we tag alerts for both parent and child resources with metadata to identify cause and dependents. We would allow for routing configuration for alert notifications based on the alert dependency tag metadata.
A main issue for the suppression of alert notifications for dependent or non-actionable alerts is timing since instances are not all polled in the same interval nor are they polled based on dependency. In order to try and prevent routing for as many dependent non-actionable alerts as possible we are considering an option to delay routing for resources that are part of a parent/child dependency chain. The notifications could be delayed until we have identified cause and dependent alerts to be routed based on user configuration. Critical alerts for which routing is suppressed based on dependency, could be routed later should the critical alert remain active once a parent resource is no longer down.
Questions for feedback:
1. What do you think of an approach that would delay routing for a short amount of time (TBD) in order to allot enough time for an alert dependency incident to get into full swing and allow the dependency algorithm to tag alerts with relevant cause and dependent metadata? This metadata would be used to determine what notifications should be routed and which should be suppressed.
2. When a critical “reachability” alert occurs for resource(s) in a dependency chain, should other alerts that occurred X #number seconds/minutes prior to the first “reachability” alert also be considered part of the alert dependency incident?
3. In your experience, how quickly does an alert dependency incident fully manifest itself in LM? Meaning from the first parent device going down, to the last dependent going down as well, how long does this typically take? Of course this can depend on what types of resources are involved so any input in that area and whether timing falls in range of (A) Less than 1 min (B) 1-3 mins (C) 3-5 mins (D) more than 5 mins, would be helpful.
4. We are starting with Ping | PingLossPercent datapoint. What other datapoints are you using as indicators of resource or instance “reachability”?
I greatly appreciate any feedback and additional questions!
Thank you,
Chris