Cole_McDonald Professor
Professor
ProfessorProfessorWe have far more WMI requests than I'd like to see on our collectors. Does anyone know if using a batchscript 'Source uses fewer TCP sockets/ephemeral ports to perform data gathering over a WMI based 'Source? The Hyper-V metrics are fairly aggressive in our environment.
ProfessorLooks as though the Windows Cluster 'Sources are all WMI as well and are quite WMI aggressive in our clustered Hyper-V environment :)/emoticons/smile@2x.png 2x" title=":)" width="20">
ProfessorAlmost all Windows-based monitoring using WMI, that is what Microsoft provided as the primary method of remote monitoring/information collection, so it's not a surprise. If you worry about using too many ports, perhaps you should lower the number of threads you are using? I think it's wmi.stage.threadpool.maxsize in the sbproxy.conf. I have not played with this option myself.
https://www.logicmonitor.com/support/collectors/collector-overview/collector-capacity/
I expect that writing a custom BatchScript for WMI calls would only help if the WMI Datasource has lots of instances AND you can collect the same data in fewer calls. You also need to balance supporting custom coding for your org vs built-in functionality.
ProfessorI've also lowered the timeout of the wmi calls to allow them to fail faster. They're bottle necking pretty hard... entirely based on available Ports and the close_wait timeout required by the TCP/IP spec. I've even gone so far as to triple the number of available ephemeral ports since the collectors we've got are used for nothing but LM. The problem is that LM doesn't seem to care if there are any ports available, it'll queue the requests no matter the state of the collector itself. Once they start timing out, they become a log jam that builds upon itself and brings the collection of metrics to a screeching halt. Since we use our data collection to prove our SLA to our customers, I have to alleviate that ... and balance it with the spend of extra VMs to increase that capacity.
We have no collector groups with > 250 devices... which is well under the capacity we were told they should be able to support. Since that doesn't seem to be the case, we're having to re-provision our VM Spend for the system and address our messaging to our customers ... we'd initially told them this change would reduce our need for extra VMs in their environments as we'd needed with SCOM (we can get into trust and security model discussions about open access vs. gateway'd single point of trust later). But those 200+ servers are choking out our two (really well balanced) collectors. So we're going to be forced to re-examine our deployment if I can't tune LM to account for the WMI load (heavily focused around HyperV and Clustered Resources).
I've reduced the frequency on nearly every WMI based 'Source we have as well as the script based ones that would use WMI to gather their data. I've easily cut the load in half from when I've started and it's still hitting the roof on the TCP ports. I've got it flowing pretty well and not dropping too much at this point, but I'll have to add more customers soon and it's going to add to the load on the collectors. (Not having to add the local resources is a sales point for us).
Ultimately, I'm just looking for other places I can trim the fat on this system to keep it within initial spec.
ProfessorBased on this, we should be able to support 800 devices / collector (large) for WMI queries and we have two of them in the group... so 1600 devices: https://www.logicmonitor.com/support/collectors/collector-overview/collector-capacity/
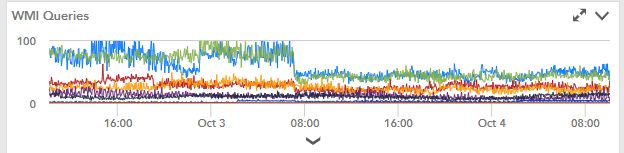
We're nowhere near that. Reducing the frequency on the Cluster and hyperv counters to 5 minutes seems to have taken off quite a bit of load. My active ports are now down to reasonable counts on the collector again.
ProfessorHere's the load drop after changing the frequency of them.