Acknowledged date for a repeating alert condition still shows the original acknowledged date
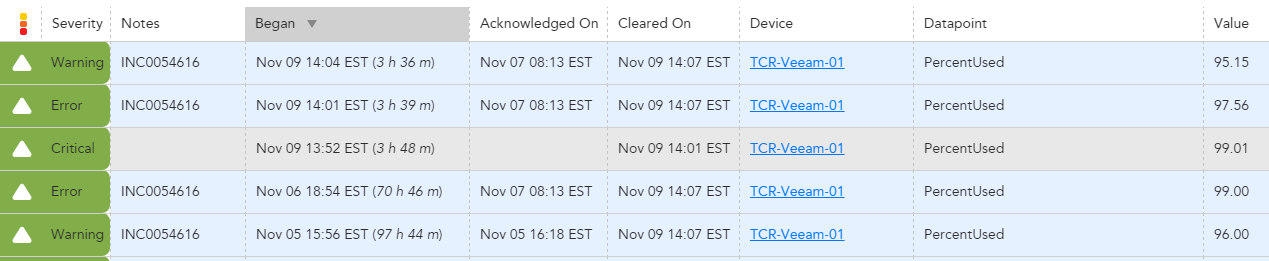
We've been seeing an issue where we get a critical alert, we are notified through our escalation chains, and we acknowledge the alert. However, the action we take to resolve the alert is only enough drop the severity on the alert to error or warning, not clear it entirely. If that alert crosses a critical threshold again it will show up as acknowledged from the first time it went critical, which will prevent all notification.
For example we have threshold for percent used on a volume at >=90 95 98. The volume hits 98%, we are notified and ack the alert, but are only able to clear space to drop the volume down to 92%. If that volume hits 98% again it will show up as already acknowledged and prevents all notifications (see below):
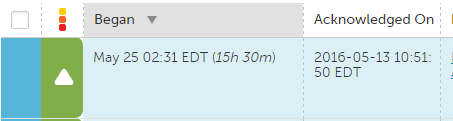
This is the expected behavior according to LM, but I don't see a benefit in this behavior and it seems risky if you expect to get alerted any time a threshold is crossed. We'd like to be able to receive a notification any time an alert crosses an threshold, regardless if it has been acknowledged at a higher severity for that alert "instance."